
Not many people think about the under-the-hood models powering ChatGPT. To the average user, the incremental updates to the world’s fastest growing product have just meant that sometimes it feels like its getting smarter (or that now a brief Thinking… dialogue appears when a hard question is asked). More technical users pay closer attention, tracking each and every little change that each of OpenAI’s nine model releases have brought to the platform.
Today’s update isn’t a little change; this is the big one. GPT-5, worthy of the full number upgrade, promises to wow ChatGPT users in a way that hasn’t happened since GPT-4’s release in 2023.
TL;DR
- GPT-5 will be the default ChatGPT model for all users (including folks on the Free plan!)
- Strongest model on coding, reasoning, tool use, and agentic benchmarks
- 400k token context window (128k output max)
- Comes in three sizes (full, mini, nano); all available via API
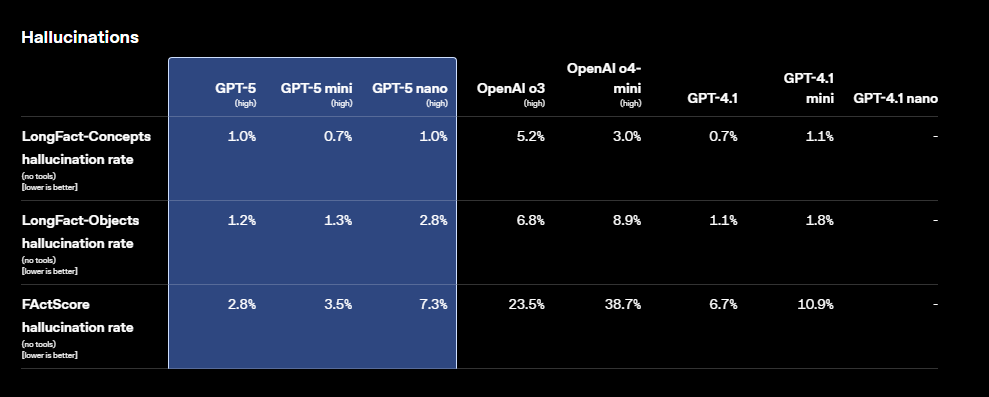
- Safer, less hallucinatory (reduced by ~80%), better instruction-following
- New dev controls:
reasoning_effort,verbosity, and plaintext custom tools - System-level router picks the right sub-model (fast vs. deep reasoning) per query
- Miscellanous ChatGPT product updatesChange the colors of ChatGPT
- New “personalities” feature preview coming
- Gmail and Google Calendar access
The fine details
GPT-5 keeps OpenAI’s promise of combining all its model variations into a single system.
In ChatGPT, you’ll be talking to a multi-model router that evaluates what type of request you’re making and dynamically delegates between “thinking” (high-reasoning) and “main” (fast-response) models. That router learns in real time for each user, incorporating model-switch patterns, preference signals, and correctness outcomes. (For example, you can say “think hard about this” in your prompt and watch it change behavior.)
GPT-5 will now powering ChatGPT by default, even for free-tier users. The fast-response model (gpt-5-main) handles most queries, and the smarter model (gpt-5-thinking) gets routed in for hard ones.
This means:
- The “Thinking…” pause actually corresponds to the router switching to a deeper model.
- Casual users will now experience GPT-5-class output for the first time.
- Most use cases (writing, analysis, research, light coding) will see tangible quality jumps.
- ChatGPT’s longform memory, web browsing, and file support are all GPT-5-native.
Under the hood
- gpt-5-thinking is the flagship model. Highest accuracy, deepest reasoning.
- gpt-5-main is faster and used for most low/medium-complexity queries.
- gpt-5-mini and gpt-5-nano are budget variants with shorter latency and lower costs.
- gpt-5-thinking-pro runs parallel test-time compute. Enterprise-grade “agent brain,” basically.
- gpt-5-chat-latest is a distinct, cheapened, non-reasoning variant powering ChatGPT Free.
All model versions are also addressable directly in the API if folks want fine-grained control. The top-end model supports an expanded 400k context window (including 128k max output tokens).
New API features:
reasoning_effort(minimal → high): trade off speed vs thoughtfulnessverbosity(low → high): steer answer length/concisenesscustom tools: plaintext tool calling with regex/CFG constraints (no JSON escaping needed)
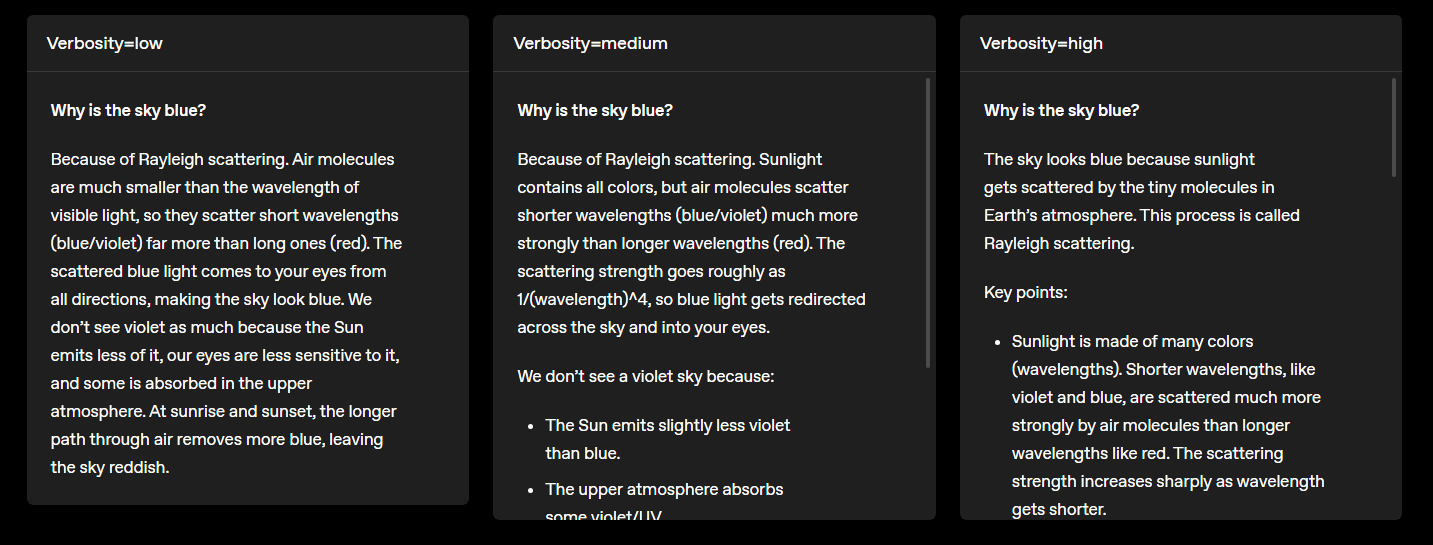
Developers can dial in tradeoffs between speed, cost, and accuracy using reasoning_effort, pick between full/nano variants, steer output verbosity, and now format tool calls in plaintext.
This enables new architectures:
- Multistage agents that plan with high-effort reasoning, then execute with nano speed.
- Chat assistants that respond fast to FAQs but escalate to full models for novel issues.
- Agents that explain their plan mid-run before calling tools, using structured preambles.
- Product builders that skip JSON pain by using plaintext tool constraints.
Enterprise users (e.g. BNY Mellon, Intercom, Notion) are already integrating GPT-5 into production workflows, claiming improvements in runtime stability, tool robustness, and versioning guarantees via snapshots.
If you want more details (and specific bench metrics), check out OpenAI’s post on GPT-5 for developers.
OpenAI vs... OpenAI
GPT-5 decisively replaces every ChatGPT model before it. Here's the lineage:

GPT-5 claims to beat all predecessors across every relevant benchmark: coding (SWE-bench, Aider polyglot), tool use (τ2-bench), long-context retrieval (MRCR, BrowseComp), instruction following (COLLIE, Scale MultiChallenge), factuality (FactScore, LongFact), and hallucination minimization.
It also supports multi-tool reasoning: parallel calls, tool error recovery, preamble messages between steps, and the ability to report progress live.
On τ2-bench telecom (a complex, mutable-environment tool use benchmark), no other model broke 50%. GPT-5 scores 96.7%. It dominates multimodal reasoning tasks (CharXiv, MMMU-Pro), passes long-context tests (up to 256k tokens) with >90% match rates, and ranks highest on instruction-following and factuality.
Claude’s most recent models is comparable on raw performance, but lags GPT-5 on agentic tasks, tool integration, and frontend code generation. Gemini 2.5 Pro is still strong on vision and long-context, but slower and more prone to hallucinations under pressure. Mistral’s open weights can’t compete on safety or task orchestration (though, reminder, OpenAI’s open source models just released this week as well).
OpenAI’s future legacy
GPT-5 is OpenAI’s first model designed to scale as infrastructure. Everything in this release (the router, the API modularity, the control parameters, the agent-first mindset) is pushing us further toward a world where intelligence is embedded in everything.
The product strategy is clear:
- GPT-4 was a demo of intelligence
- GPT-5 is a platform for deploying it
The future is obvious: longer context, tighter agent integration, more real-world interfaces, and smaller deployment footprints for on-device execution. All of that will now built on GPT-5’s spine and streamlined product experience.