
Gemini 3 is here. Is it state of the art? How will it feel for normal humans inside Search and the Google’s Workspace apps? How does it compare to GPT-5.1, Claude Sonnet 4.5, DeepSeek, and friends?
Let’s see.
TL;DR
- Google launched Gemini 3 Pro as its new flagship model and immediately wired it EVERYWHERE. (Gemini app, AI Mode in Search, AI Studio, and Vertex AI on day one).
- A higher-gear “Deep Think” mode sits on top of Pro for heavy reasoning tasks, gated behind extra safety review for Google AI Ultra subscribers.
- Benchmarks: Gemini 3 Pro leads the LMArena leaderboard, pushes Humanity’s Last Exam, GPQA Diamond, ARC-AGI-2, MMMU, and MathArena Apex to new scores (with Deep Think pushing those numbers higher again).
- Google built long-horizon agent behavior into this generation: Gemini Agent for email and life tasks, Antigravity for software creation, and stronger planning benchmarks such as Vending-Bench 2.
What Gemini 3 actually is
Gemini 1 pushed “native multimodality” and longer context. Gemini 2 and 2.5 leaned into reasoning and early agents (with Gemini 2.5 Pro sitting at the top of LMArena for half a year).
Gemini 3 tries to combine all of that into a single flagship:
- Model family. Gemini 3 Pro at launch, with more variants to follow. Deep Think sits as a special mode over Pro rather than a separate product.
- Placement. AI Mode in Search, Gemini app, AI Studio, Vertex AI, Gemini CLI, and Antigravity all get Gemini 3 Pro from day one
- Use cases. Learn anything, build anything, plan anything. That is the official framing, and Google attempts to back it with concrete flows: family recipe translation from handwritten scrawl, automated question sets from lecture video, analysis of sports footage, complex UI generation, long-horizon planning tasks, and automated workflows that run through email, calendars, and the browser.
From a technical perspective, there are three pillars here that matter:
1. Reasoning benchmarks
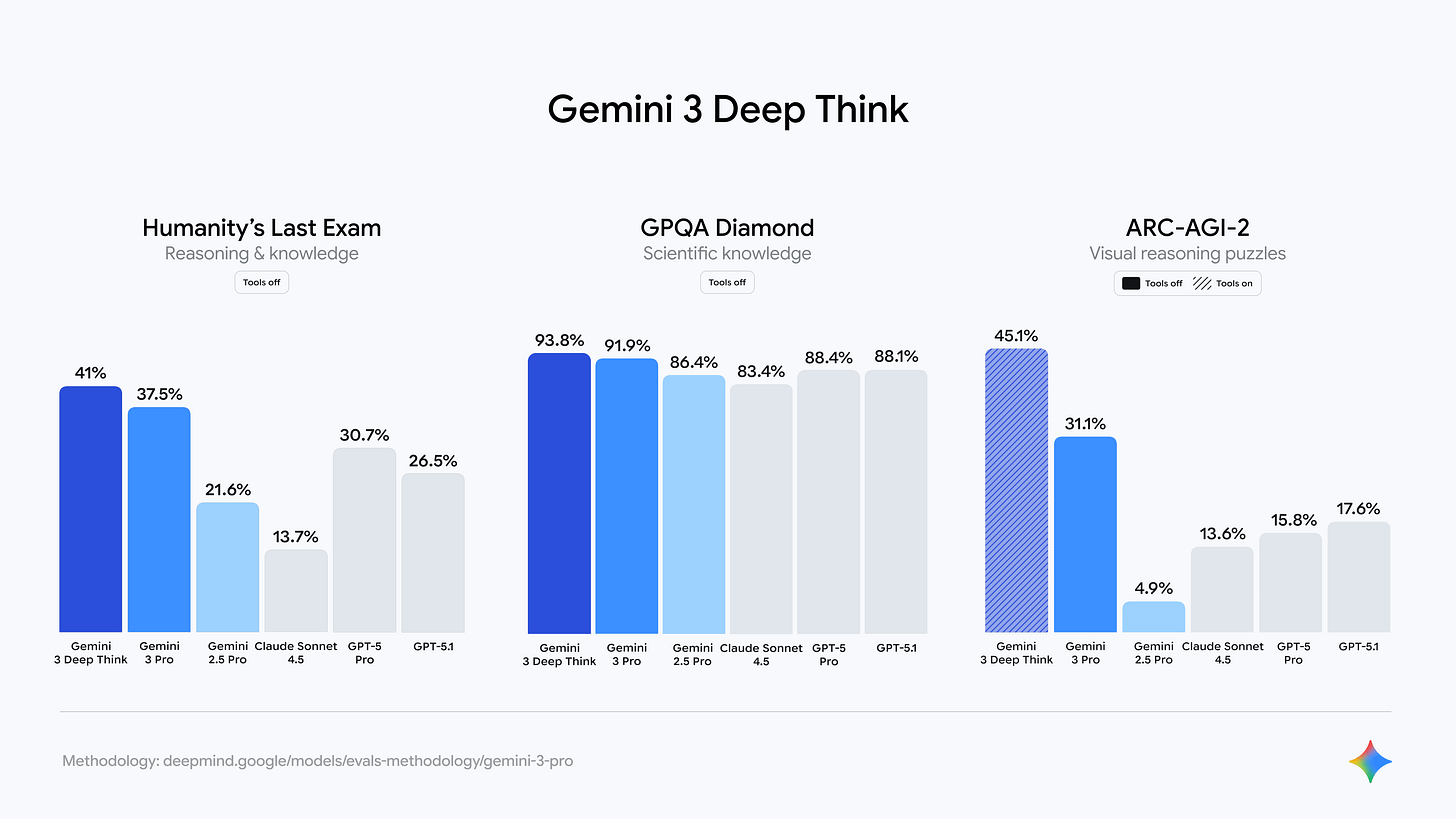
Gemini 3 Pro surpasses Gemini 2.5 Pro on every major AI benchmark worth caring about.
- LMArena leaderboard: 1501 Elo, first place
- Humanity’s Last Exam: 37.5% (Pro) and 41.0% (Deep Think) without tool use
- GPQA Diamond: 91.9% (Pro) and 93.8% (Deep Think)
- ARC-AGI-2 (with code execution, ARC Prize Verified): 45.1% for Deep Think
- MathArena Apex: 23.4%, a new top result among frontier systems
- SimpleQA Verified: 72.1%, which signals progress on factual accuracy tests
Those benchmarks stress conceptual reasoning, science, and math. The takeaway: Gemini 3 sits clearly in the frontier band. You can argue about which inch of that band wins your favorite leaderboard; you cannot argue that Gemini 3 belongs in that tier.
2. Multimodal and context
Gemini 3 goes hard on multimodal:
- MMMU-Pro: 81%
- Video-MMMU: 87.6%
These are tests where the model has to understand and reason over images and videos. Gemini 3’s longer context (over models like GPT 5.1) can ingest long papers, codebases, or lecture series and supposedly still reason accurately across visual and textual information in one pass.
Looking at Google’s focus on “generative interfaces,” it’s not hard to see where they’re planning to go: Layout-heavy answers, embedded simulations, and on-the-fly UI that responds to your query.
3. Agents, coding, and “plan anything”
On the coding side:
- Gemini 3 Pro tops the WebDev Arena leaderboard with 1487 Elo
- Terminal-Bench 2.0: 54.2%, which measures ability to control a computer via terminal and tools
- SWE-bench Verified: 76.2%, a major jump from Gemini 2.5 Pro’s 59.6% in earlier public comparisons and closer to Claude Sonnet’s 77.2% record (whoops)
On longer-term planning:
- Gemini 3 Pro leads Vending-Bench 2, which simulates running a vending machine business for a full year and checks consistent tool use and planning over many steps
How this plays for regular users
Everyone else cares about “what happens when I open Search or the Google Docs”. Here is how this release hits you if you live in Google land.
Search: AI Mode from day one
Gemini 3 now runs AI Mode in Search from launch, which is a first for Google. Earlier model versions shipped into Search weeks or months after model announcements.
Changes you will see:
- For complex queries, AI Mode can skip standard blue links and present a full answer panel. Reuters reports Google executives described layouts that look closer to full web pages, with images, interactive elements, and simulations, and less emphasis on traditional search results.
- Google’s “query fan-out” technique has been upgraded, meaning the system breaks your question into sub-queries, hunts across the web, and then recombines the results with better awareness of intent.
This feels powerful and also brutal for publishers. More of the “answer” lives inside Google’s glass box. Reuters calls the redesign a further hit to sites that rely on search traffic for revenue.
Gemini app: less flattery, more spine
The Verge calls Gemini 3 “less prone to empty flattery” than ChatGPT and highlights that Google explicitly tuned responses to be concise, direct, and less sycophantic.
Google’s own blog leans into this: Gemini 3 aims to trade cliché and flattery for “genuine insight,” with the model more willing to give blunt corrections instead of mirroring your opinion.
For normal use, that should mean:
- Fewer “great idea!” responses when the idea sucks.
- More “this plan fails because X and Y” responses when you ask it to reason about projects or strategies.
- Less sugar on top of obviously unsafe or misguided requests.
For the everyperson, this is welcome, and is a clear response to OpenAI’s own model tweaking away from sycophancy. AI that acts as a mirror for human ego has limited use.
How Gemini 3 stacks up against GPT-5.1, Claude Sonnet 4.5, DeepSeek, and others
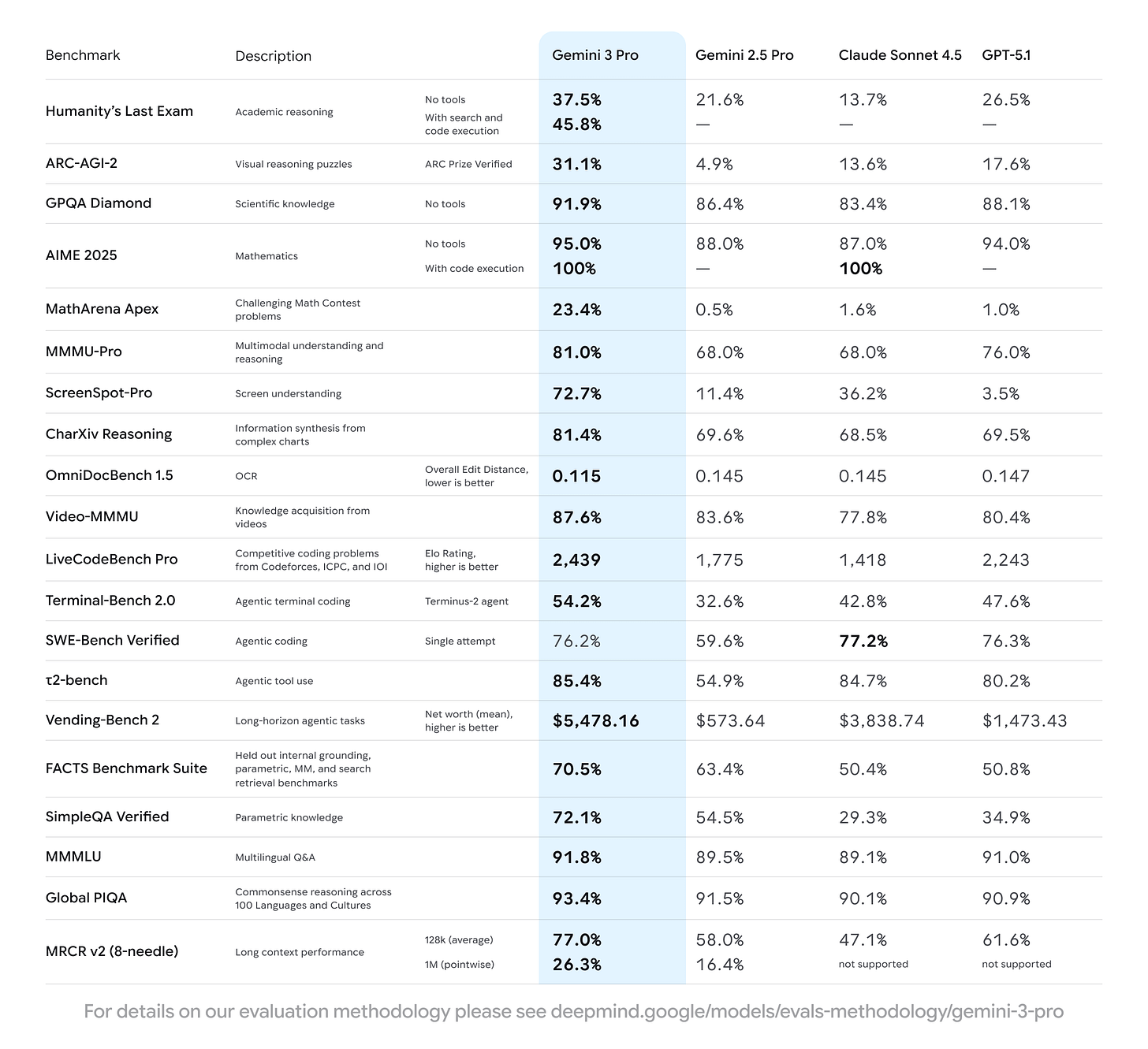
Independent and semi-independent sources paint this rough picture:
- Humanity’s Last Exam. Gemini 3 hits 37.4 on HLE (even higher with Deep Think), above the previous record from GPT-5 Pro at 31.64.
- LMArena. Gemini 3 sits comfortably at the top of the leaderboard. Google cites 1501 Elo; The Verge also highlights this.
- Math and science. DeepSeek R1 still crushes AIME-style math benchmarks with scores above 80%, while Gemini 3 leads on MathArena Apex.
- Coding. Claude 4.5 Sonnet still holds a public lead on SWE-bench Verified at around 77.2% in third-party comparisons, while Gemini 2.5 Pro lagged at 59.6%. Google now claims Gemini 3 Pro hits 76.2% on SWE-bench Verified, which closes the gap for agentic coding tasks.
- Multimodal. Gemini 3’s MMMU-Pro and Video-MMMU scores are among the best disclosed results in general-purpose models (no surprise that Google is leaning into that with heavy multimodal marketing).
Skywork’s pre-release comparative testing between GPT-5.1 and Gemini 3 lines up with this: GPT-5.1 leads for pure text work, long-form writing, steady API behavior, and some enterprise automation, while Gemini 3 feels stronger for visual work, multimodal flows, and large-document analysis (with that sweet 1M token context).
My read (getting down to it)
If you ignore marketing and look at use case clusters:
- Text-heavy work, agents in mature ecosystems. GPT-5.1 remains strong, with good tooling, dev docs, and stable behavior.
- Pure coding. Claude Sonnet 4.5 still has an edge on SWE-bench and code-focused workflows, though Gemini 3’s jump on coding benchmarks will pressure Anthropic hard.
- Multimodal, long-context research, web-like UI. Gemini 3 sits at the front of the line for now, with no clear response from other foundation labs.
- Math and reasoning extremals. DeepSeek R1 renders that contest strange by pushing high AIME scores at tiny training cost, which proves that pure “intelligence” is still not exclusive to big US labs.
So does Gemini 3 “win”? For many users inside Google’s world, yes, because integration matters more than a few percentage points. For teams already locked into OpenAI or Anthropic ecosystems, Gemini 3 exists more as competitive pressure than a drop-in replacement.
The smarter move, as always, is getting cozy with multiple models: use Gemini 3 where its multimodal and context strengths matter, GPT-5.1 or Claude where their ecosystems and coding strengths shine, DeepSeek where cost and math dominate. While the foundation labs continue to duke it out, it’s clear that the consumer wins when embracing it all at once.
Antigravity: Google’s agent-first IDE
I’d be remised to not include a short blurb in here on Antigravity (which probably deserves its own post later). Antigravity is Google’s new developer environment (yeah, another one) that centers agents rather than autocomplete snippets. It feels like a direct response to Cursor’s agent-based overhaul earlier this Fall.
Core traits:
- Agent-first surface. Agents live in a dedicated panel with direct access to the editor, terminal, and an integrated browser. They plan, execute, and validate work without constant prompting.
- Two main views:Editor view: familiar IDE experience with agent support on the side.
- Manager view: a control room to spin up multiple agents across projects and watch them run in parallel.
Artifacts. As agents work, they emit Artifacts: task lists, detailed plans, screenshots, browser recordings, and other traces. Google argues these are easier to audit than raw tool-call logs.
Model mix. Gemini 3 Pro sits at the center, backed by the Gemini 2.5 Computer Use model for browser control and the Nano Banana image editing model. Antigravity also supports Claude Sonnet 4.5 and a GPT-OSS model for teams that want multi-vendor setups.
Availability and cost. Public preview, free to use with “generous” Gemini 3 Pro rate limits that reset every five hours.
If you already use Cursor, Copilot Workspace, or similar tools, Antigravity fits the same trend: IDEs where agents manage work streams, with humans supervising and steering rather than typing every line.
The differentiator here is tight integration with Google’s own models, browser, and safety stack plus explicit support for artifact-based traceability (which matters if you ever need to defend an agent’s behavior to a security team).
Gemini 3 is an impressive showing for Google, and is the first time I’ve seen a responsibly clear product vision on their AI-side. I like the emphasis on reduced flattery, explicit planning benchmarks, and real agent products instead of loose demos. I do worry about AI Mode in Search turning the open web into a corpus feeder with no path back for publishers and about agentic systems that touch browsers, terminals, and personal data with incomplete transparency.
For builders and power users, though, the practical message is simple: Gemini 3 belongs in your toolbelt. Treat it as one strong system among several, wire it into workflows that benefit from multimodal context and strong planning, and keep a human hand on the kill switch while the industry figures out how aggressive agent automation should become.